
Livelli audio e loudness – sesta parte
Processori multibanda
In un processore multibanda l’audio viene diviso in un certo numero di bande di frequenza, e ciascuna viene compressa, limitata ed espansa individualmente. Un esempio è mostrato dalla figura che segue.
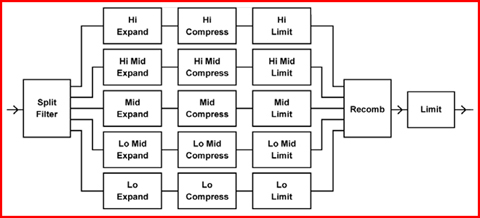
I processori digitali sono dotati di rivelatore look-ahead e una perfetta ricombinazione delle bande, superando quindi il maggiore problema dei sistemi multibanda analogici. I vantaggi del processamento multibanda sono:
- massima intelligibilità del parlato
- si evitano la modulazione e le perdite nei segnali ad alta frequenza
- si può ottenere il massimo loudness e una minore limitazione
invasiva - si può utilizzare il bilanciamento spettrale per aiutare a ottenere
una specifica risposta in frequenza ad un determinate livello
Bilanciamento spettrale
Parte della facilità d’uso insita nella catena audio analogica è andata persa nella produzione digitale, ma la cosa più importante è che non c’è più alcuna restrizione degli alti livelli alle alte frequenze, così che la voce umana può risultare troppo brillante per via dell’equalizzazione necessaria a ottenere la pulizia ai bassi livelli. Nei processori multibanda si può utilizzare il bilanciamento dinamico spettrale per compensare l’incremento di non linearità del nostro orecchio ai bassi livelli e per evitare un’eccessiva brillantezza agli alti livelli. Utilizzando questa tecnica è possibile incrementare, per esempio le basse e le alte frequenze ai bassi livelli, ma avere una risposta in frequenza piatta o persino tagliata agli alti livelli. Il bilanciamento dinamico spettrale si ottiene utilizzando differenti soglie di compressione, rapporti e livelli nelle diverse bande di un processore multibanda.
Controllo del loudness
Se il materiale audio si limita alla sola voce umana, una semplice stima del loudness basata sulla norma IEC 268-10 (misuratore di livello PPM) o una misura Leq pesata dovrebbe essere tutto ciò che è necessario per assicurare la consistenza del livello e il bilanciamento all’interno e tra i programmi broadcast. Tecnici esperti possono, per esempio, ottenere buoni risultati con misuratori PPM quando bilanciano i dialoghi, perché un approccio di “quasi picco” è abbastanza corrispondente con il loudness apparente della voce umana. Con i progressi degli ultimi anni delle capacità di processamento in tempo reale, è ora possible misurare e controllare il loudness anche di segnali più complessi del parlato. Quando si desidera controllare il loudness automaticamente in tempo reale, è importante che i costruttori delle apparecchiature non cerchino di inventarsi un proprio standard ma piuttosto facciano affidamento sulla vasta ricerca di base fatta dai pionieri del loudness più di due decenni fa. La misura del loudness di segnali complessi dovrebbe essere basata su uno standard internazionale, come l’ISO 532, che tiene conto anche dei fattori spettro e mascheramento. Una serie di curve isofoniche è definita dallo standard ISO 226, che richiama le curve isofoniche di Fletcher e Munson. La figura che segue rappresenta un
esempio di processore di loudness in tempo reale con funzioni multibanda.
esempio di processore di loudness in tempo reale con funzioni multibanda.
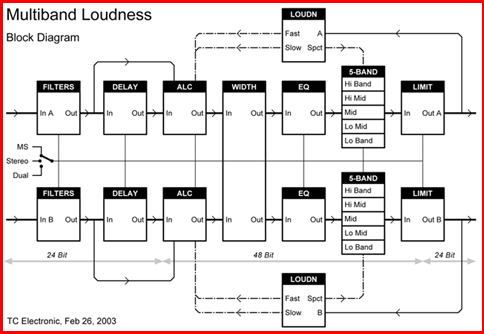
L’algoritmo utilizza un ampio range dinamico con un’headroom interna ben al di sopra dei 24 bit per evitare sovraccarico a breve termine (short-term overload) e clipping senza sacrificare la risoluzione. È possibile una latenza di circa 1 mS utilizzando una combinazione di loudness stimato e aggiustamento nel lungo termine. Le stime rapide del loudness si basano su misure pesate, e il livello viene corretto di conseguenza utilizzando costanti di tempo variabili. Gli effetti a breve termine vengono moderati da un processore multibanda e da un limitatore istantaneo in uscita, mentre il loudness a lungo termine può essere soggetto a ulteriori regolazioni includendo una controreazione basata sulla percezione. Un algoritmo con una tipologia che segue per lo più questo esempio ha dimostrato di poterfar raggiungere un loudness e dei risultati spettrali straordinariamente consistenti.
Formati multipli
Nel digital broadcast, l’audio può essere in un formato che va dal mono al multitraccia, dallo stereo al multicanale, e persino in un mix di questi formati. Di conseguenza, i broadcasters di tutto il mondo stanno installando processori e interfacce per far fronte a tali necessità nelle aree chiave della loro infrastruttura. Per i processori di dinamica multicanale, dovrebbero essere disponibili differenti tipologie di linking. I 5 canali principali necessitano di diverse modalità per il film se comparato alla musica, mentre il canale LFE normalmente non andrebbe linkato con gli altri. Dato che i programmi 5.1 sono più spesso film o programmi TV ad alto profilo, dovrebbero essere disponibili curve diverse per, ad esempio, alzare il livello dei dialoghi, lasciare intatto il livello del materiale di riferimento e limitare l’headroom.
La riduzione dei dati
L’audio digitale lineare contiene una gran quantità di informazioni in eccesso, così per conservare l’ampiezza di banda molti formati di trasmissione traggono parecchio vantaggio dalla riduzione dei dati per l’audio e il video. Tra gli utilizzatori dell’audio più preparati c’è in genere accordo sul fatto che la qualità audio può rimanere intatta con una riduzione dei dati che va da 1:6 e 1:8, se l’audio a monte della trasmissione viene mantenuto ad alta risoluzione e senza distorsione di alias. Con il codec AAC la banda di trasmissione richiesta per mantenere un audio trasparente scende ora a circa 64 Kbps per canale.
I metadati
Nella trasmissione digitale, i segnali audio possono essere accompagnati da alcuni dati, contenenti le informazioni sull’audio, chiamati metadati. L’audio in sé può essere lineare o con dati ridotti, ma il formato scelto per la riduzione può spesso essere considerato separatamente dai metadati. I metadati possono avere differenti complessità. Da quelli base, come negli sviluppi più vecchi come l’interfaccia AES3, Eureka 147 DAB o il Dolby AC3, fino ai descrittori di contenuto più approfonditi, come nell’MPEG-4 e nell’MPEG-7.I metadati audio base includono solo le informazioni su come i canali sono utilizzati, ma le nuove implementazioni permettono all’utilizzatore persino di scomporre, di ri-mixare l’audio e di elaborarlo in varia maniera. La transizione all’Alta Definizione e all’audio 5.1 hanno esasperato il problema del loudness. Il problema principale non è tanto l’incremento dei canali dallo stereo ai sei canali dell’audio 5.1, quanto la tecnologia supplementare necessaria a ricevere, processare e trasmettere l’audio 5.1 nella catena audio. Per fortuna, ci sono parecchie opzioni pratiche per i broadcasters per affrontare questo problema, e per loro è diventato più semplice adottarle grazie alla recente introduzione di una tecnologia più semplice e maggiormente integrata di processamento del segnale. Per esempio, fino a poco tempo fa, era normale per una catena di processamento del segnale HD comprendere diversi moduli di processamento discreti e apparati dedicati. Tutte queste apparecchiature erano necessarie per affrontare le operazioni di conversione video e audio, di multiplex, upmix e codifica. Adesso questa catena di apparati può essere sostituita da una sola scheda, riducendo così i costi e la complessità. È ora possibile integrare tutte le funzionalità necessarie al 5.1 in un solo modulo, senza compromettere funzionalità e qualità. Prima di dare uno sguardo ai diversi approcci disponibili per il controllo del loudness anche tramite i metadati, è importante esaminare alcune delle questioni che stanno alla base del problema.
Gestire i livelli audio
Fin dalla sua comparsa, il sistema Dolby Digital includeva un dispositivo per il controllo del loudness. Questa funzionalità, comunemente conosciuta come normalizzazione dei dialoghi, era stata inclusa per consentire ai broadcasters di operare a differenti livelli di loudness, con le differenze di loudness che potevano essere trattate a casa dell’utente dallo stesso decoder Dolby. L’idea, in generale, era che tutti i contenuti dovessero includere un parametro di metadati, chiamato dialnorm, che indicasse il livello nominale dei dialoghi nel programma. Il valore dialnorm viene dunque presentato all’encoder Dolby Digital che lo invia al decoder casalingo, dove esso viene ricevuto e applicato al segnale audio decodificato, allo scopo di modificarne il livello. Quando lo spettatore cambia i canali o quando il broadcaster commuta da segmento a segmento, il valore dialnorm associato viene utilizzato dal decoder audio per regolare dinamicamente il livello audio generale, in modo da conservare un loudness il più possibile consistente.

Purtroppo, invece di risolvere i problemi di loudness tra i diversi canali e segmenti, la normalizzazione dei dialoghi ha spesso peggiorato le cose. Ciò è generalmente il risultato delle incongruità nelle impostazioni del dialnorm durante la creazione del programma, o quando il video viene ricevuto e processato da una struttura. Questo può accadere quando il contenuto viene creato, se il valore non viene correttamente impostato, o durante il processo di acquisizione o di ingest, quando i metadati audio vengono rimossi dalle alcune delle apparecchiature o viene inserito valore errato. Allo stesso modo, durante la produzione o all’interno un master control, i valori di dialnorm possono non essere correttamente impostati (lasciati, per esempio, ai valori di default), o l’audio può essere può essere stato modificato ma i valori di dialnorm possono non essere stati correttamente reimpostati. L’effetto finale di tutte queste eventualità è che i livelli audio uditi dallo spettatore sono spesso regolati utilizzando valori errati di dialnorm, risultando dunque instabili e inappropriati.
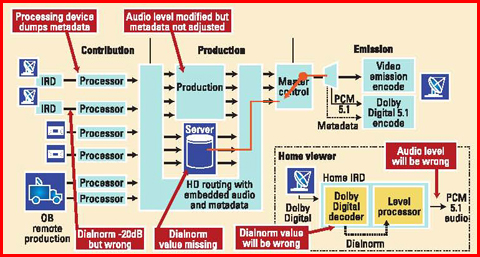
Le tre soluzioni più comuni per questi problemi di audio sono: metadati dinamici, metadati statici e misura del loudness con controllo “al volo” dei livelli audio. I metadati dinamici rappresentano la soluzione originaria. Essa consiste in una combinazione di pratiche di produzione virtuose, che assicurino che tutti i contenuti creati o ingestati abbiano un valore di dialnorm appropriato, e di apparati ben progettati, in modo da assicurare che i metadati siano mantenuti attraverso tutta la catena e consegnati intatti all’encoder di trasmissione. Sebbene questo modello sia recentemente divenuto più efficace così da essere stato da poco ratificato nello standard SMPTE-2020, che specifica le pratiche di trasporto dei metadati Dolby nello spazio ausiliario del video HD e SD-SDI, esso non viene ancora utilizzato in molte delle strutture esistenti. Questo perché i broadcasters devono essere sicuri che tutti i processi audio utilizzati nella loro struttura lascino passare e regolino i metadati audio se e quando il contenuto audio viene modificato. Sfortunatamente, la realtà è che molte strutture HDTV utilizzano un grande numero di apparecchiature progettate e sviluppate prima che esistesse lo standard SMPTE-2020, rendendo impossibile la sopravvivenza dei metadati attraverso tutta la catena. I metadati statici rappresentano
l’estremo opposto di questo ventaglio di possibilità. Questo modello presuppone la necessità di produrre tutti i contenuti con un livello dei dialoghi conosciuto e l’impostazione del corrispondente livello di dialnorm in maniera statica nell’encoder di trasmissione. Ciò richiede una collaborazione stretta con tutti i fornitori esterni di contenuti per essere sicuri che tutti i contenuti forniti siano mixati con il livello di loudness tabilito come obiettivo. Per i contenuti non dal vivo forniti su nastro o su file, è possibile misurare il loudness dell’intero programma e riprocessare l’audio per essere sicuri che esso corrisponda al livello dei dialoghi desiderato. Ma per i contenuti dal vivo o che vengono forniti in tempo reale sotto forma di streaming, non è possibile realizzare questo modello in maniera efficace perché il livello dei dialoghi è una funzione dell’intero programma o di parte di esso, e questi devono essere interamente ricevuti prima di poter conoscere esattamente il livello dialnorm. La misura e il controllo del livello “al volo” rappresentano la terza possibilità. Questo procedimento ignora i metadati in ingresso e aggiunge un’apparecchiatura alla fine della catena, apparecchiatura che misura il loudness del programma e contemporaneamente imposta di conseguenza il valore di dialnorm o processa l’audio perché corrisponda al valore di dialnorm scelto come obiettivo.
l’estremo opposto di questo ventaglio di possibilità. Questo modello presuppone la necessità di produrre tutti i contenuti con un livello dei dialoghi conosciuto e l’impostazione del corrispondente livello di dialnorm in maniera statica nell’encoder di trasmissione. Ciò richiede una collaborazione stretta con tutti i fornitori esterni di contenuti per essere sicuri che tutti i contenuti forniti siano mixati con il livello di loudness tabilito come obiettivo. Per i contenuti non dal vivo forniti su nastro o su file, è possibile misurare il loudness dell’intero programma e riprocessare l’audio per essere sicuri che esso corrisponda al livello dei dialoghi desiderato. Ma per i contenuti dal vivo o che vengono forniti in tempo reale sotto forma di streaming, non è possibile realizzare questo modello in maniera efficace perché il livello dei dialoghi è una funzione dell’intero programma o di parte di esso, e questi devono essere interamente ricevuti prima di poter conoscere esattamente il livello dialnorm. La misura e il controllo del livello “al volo” rappresentano la terza possibilità. Questo procedimento ignora i metadati in ingresso e aggiunge un’apparecchiatura alla fine della catena, apparecchiatura che misura il loudness del programma e contemporaneamente imposta di conseguenza il valore di dialnorm o processa l’audio perché corrisponda al valore di dialnorm scelto come obiettivo.
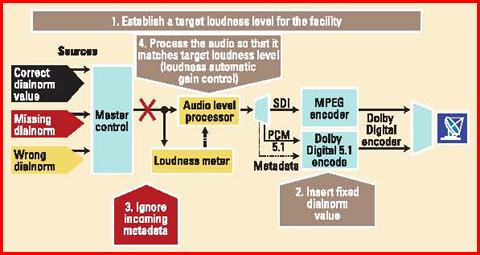
Questo schema è, grosso modo, equivalente a un Controllo Automatico di Guadagno (AGC) posto all’uscita della struttura, che utilizza il loudness per il controllo del segnale. In ogni modo, poiché quella del loudness è una misura che si suppone integrata lungo un periodo di tempo piuttosto lungo (idealmente l’intera durata del programma o del segmento), questo metodo può dare dei problemi. Per esempio, in una scena silenziosa il livello di loudness, persino il livello di loudness dei dialoghi, può risultare temporaneamente basso. Se questo basso livello viene utilizzato come riferimento per alzare il livello audio, e se la scena silenziosa è seguita da una scena ad alto volume, allora l’incremento del louness verrà amplificato e risulterà come un innalzamento abnorme e indesiderato del livello audio. Tutto ciò va contro l’obiettivo originario della normalizzazione dei dialoghi e del controllo del range dinamico ipotizzato dal formato Dolby Digital. In definitiva, la soluzione migliore ai problemi di loudness dipenderà dalla singola struttura, e specialmente dal livello di controllo che il broadcaster ha sui contenuti in entrata, in modo particolare quelli “live” o in streaming. In tutte e tre queste soluzioni, si raccomanda che il livello di loudness venga continuamente misurato e comparato al valore di dialnorm in uscita, sia esso statico o dinamico.