
Livelli audio e loudness
L’avvento della televisione digitale ha evidenziato in tutto il mondo un crescente problema riguardante i dislivelli del segnale audio, specialmente quando programmi ad ampia dinamica sono seguiti da altri programmi con una dinamica molto stretta, come ad esempio promo, pubblicità o programmi sportivi. Improvvise differenze di loudness tra i programmi radiotelevisivi, e persino al loro interno, rappresentano un problema ben conosciuto da molto tempo, ma la recente introduzione della tecnologia digitale, combinata con la trasmissione contemporanea di contenuti analogici e digitali, ha fatto sì che questo problema sia diventato sempre più rilevante. Gli ascoltatori e i telespettatori stanno mostrando sempre più interesse riguardo alle improvvise variazioni del loudness dei programmi, salti che sono particolarmente evidenti quando si fa “zapping” tra le varie televisioni DVB (Digital Video Broadcasting) europee e tra i canali radio. Le differenze di loudness tra i dialoghi dei film e le interruzioni pubblicitarie, che sono altamente compresse, vengono percepite sempre più come parecchio irritanti. In questi casi si può osservare sia del sotto-livellamento che del sovra-livellamento, con differenze che spesso arrivano a più di 15 dB. Vediamo ora di dare una definizione di loudness:
esso è l’attributo di un suono che determina l’intensità della sensazione uditiva e che dipende principalmente dall’ampiezza dell’onda sonora.
Il loudness, però, non è assolutamente dipendente dai livelli di picco del segnale audio ma dalle sue caratteristiche psicoacustiche, prese nel loro complesso:
- Frequenza
- Intensità (ampiezza RMS)
- Durata
- Mascheramento
Il loudness, dunque, non è dipendente dai livelli di picco del segnale audio. Non solo: le misurazioni del livello utilizzate in ambito broadcast, che fanno uso della rilevazione del livello di picco, fanno sembrare più alto il materiale audio dotato di una minore dinamica. Come aggravante, nei CD e nella produzione commerciale viene fatto un uso eccessivo della compressione di dinamica pura e semplice. Questo provoca, come ampiamente documentato, alcuni effetti collaterali, tra i quali una certa quantità di distorsione in apparecchiature consumer, nei convertitori di campionamento e nei vari tipi di codificatori, e dunque si raccomanda una certa interpretazione tra la misura del livello e quella del loudness. Poiché il giudizio sul volume di un programma è molto soggettivo, alla ricerca di una misura del loudness che lo sia meno, è necessario accettare come inevitabile una certa variabilità tra gli ascoltatori e anche in uno stesso ascoltatore, intendendo con questo che la valutazione del volume, persino in una stessa persona, è attendibile fino a un certo punto e dipende dall’orario, dallo stato d’animo, dal grado di attenzione e da molti altri fattori. La Variabilità tra gli Ascoltatori (BLV) raggiunge un ulteriore grado di confusione quando vengono introdotte ulteriori variabili, quali il sesso, la cultura, l’età e altro ancora. Nella pratica quotidiana si ha una confusione persino maggiore per via dei vari sistemi di riproduzione adottati.A causa di tutte queste variabili, una generica misura del loudness ha senso solo se basata su riferimenti soggettivi ampi e su solide statistiche. Una serie di ricerche e di valutazioni riguardanti un modello per il loudness ha prodotto due generiche misure di loudness (Leq) abbastanza attendibili, chiamate A e M. Di fatto, un misuratore di quasi-picco (PPM) ha dimostrato un giudizio migliore del loudness rispetto alle misure pesate Leq(A) e Leq(M). Anche se usata solo per il parlato, la misura Leq(A) è povera di picchi e non si comporta bene con la musica e gli effetti. La scelta di un algoritmo di misura a bassa complessità è ben conosciuta come Leq(RLB), ed è ora parte dello standard ITU-R BS.1770, che definisce la misura del loudness e del vero livello di picco.
Tolleranza del range dinamico
Poiché si tratta di un termine che d’ora in avanti ripeteremo fino alla noia, è necessario dare qui una definizione al concetto di headroom:
essa rappresenta la differenza (espressa in dB) tra il livello di picco e il livello medio di un segnale audio. La headroom indica dunque il margine che ha disposizione il livello medio di un suono prima di raggiungere il picco massimo consentito, prima cioè della distorsione.
essa rappresenta la differenza (espressa in dB) tra il livello di picco e il livello medio di un segnale audio. La headroom indica dunque il margine che ha disposizione il livello medio di un suono prima di raggiungere il picco massimo consentito, prima cioè della distorsione.
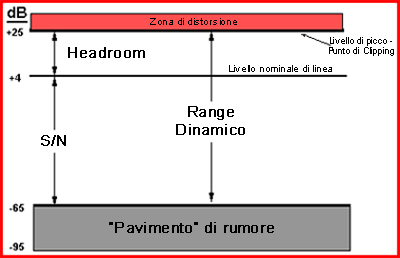
La televisione digitale (DTV) può trasportare un ampio range dinamico audio, ma questo aspetto non è in genere importante per il consumatore. Ciò che importa di più è la consistenza del loudness, all’interno dei programmi e tra i programmi, e anche l’intelligibilità del parlato. I consumatori hanno una Tolleranza al Range Dinamico (DRT) specifica per la loro situazione di ascolto (parte sinistra della figura successiva). La DRT è definita come la finestra media preferita, con un certo margine per il livello di picco (headroom) al di sopra di essa. Il livello medio deve essere contenuto entro confini determinati al fine di mantenere l’intelligibilità del parlato, e per evitare che la musica o gli effetti siano fastidiosamente troppo alti o troppo bassi.
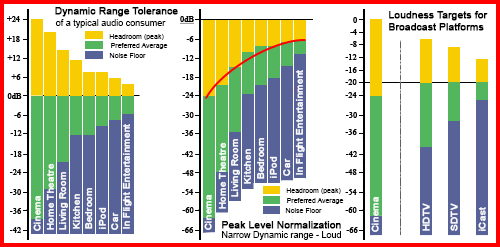
I consumatori preferiscono basse variazioni del loudness in determinate condizioni di ascolto. Sinistra: Tolleranza del Range Dinamico del consumatore medio alle differenti condizioni di ascolto. Centro: Con la normalizzazione dei picchi, il materiale a basso contenuto dinamico alza quello con un contenuto più alto (linea rossa). Destra: Variazione di loudness appropriata per le differenti piattaforme broadcast.
In definitiva due sono le cose che il telespettatore medio pretende durante l’ascolto di un programma:
- poter sentire sempre i dialoghi
- non dover sempre cambiare il volume con il telecomando
Va notato che i telespettatori molto spesso protestano per l’audio quando la dinamica è troppo ampia, piuttosto che quando essa è troppo stretta. La sola situazione riproduttiva in cui un range dinamico ampio è percepito come un bene è in una sala cinematografica. Di conseguenza, è un interesse primario per il broadcaster dare intelligibilità ai dialoghi e più consistenza al loudness dei programmi che trasmettono, non solo per quanto riguarda la HDTV ma anche per tutte le altre piattaforme. La combinazione tra la storia del loudness e la DRT dell’ascoltatore finale dovrebbe dunque dare i suoi frutti nella produzione futura. Il tecnico, che potrebbe anche non essere un esperto di audio, dovrebbe essere in grado di lavorare con consapevolezza nell’ambito di una determinata piattaforma di distribuzione e con risultati che siano prevedibili anche quando il programma viene transcodificato in un’altra piattaforma. Un misuratore di livello dovrebbe dunque utilizzare un display dotato di un codice di colori per identificare facilmente il livello ottimale (verde), quello che si trova sotto il livello del rumore (blu) e gli eventi a volume elevato (giallo). Lo scopo è quello di concentrare il restringimento del range dinamico intorno a un loudness medio, quindi, automaticamente, evitando di far scomparire le differenze tra gli elementi in primo piano e quelli in sottofondo in un mix. Quando i tecnici di produzione definiscono i limiti per l’audio, generalmente si mantengono entro di essi; di conseguenza, durante la distribuzione si richiede un minore intervento sulla dinamica. È da notare come siano diversi i requisiti del broadcasting rispetto a quelli del cinema.